AudioGenie – A multimodal audio generation tool developed by Tencent AI Lab
What is AudioGenie?
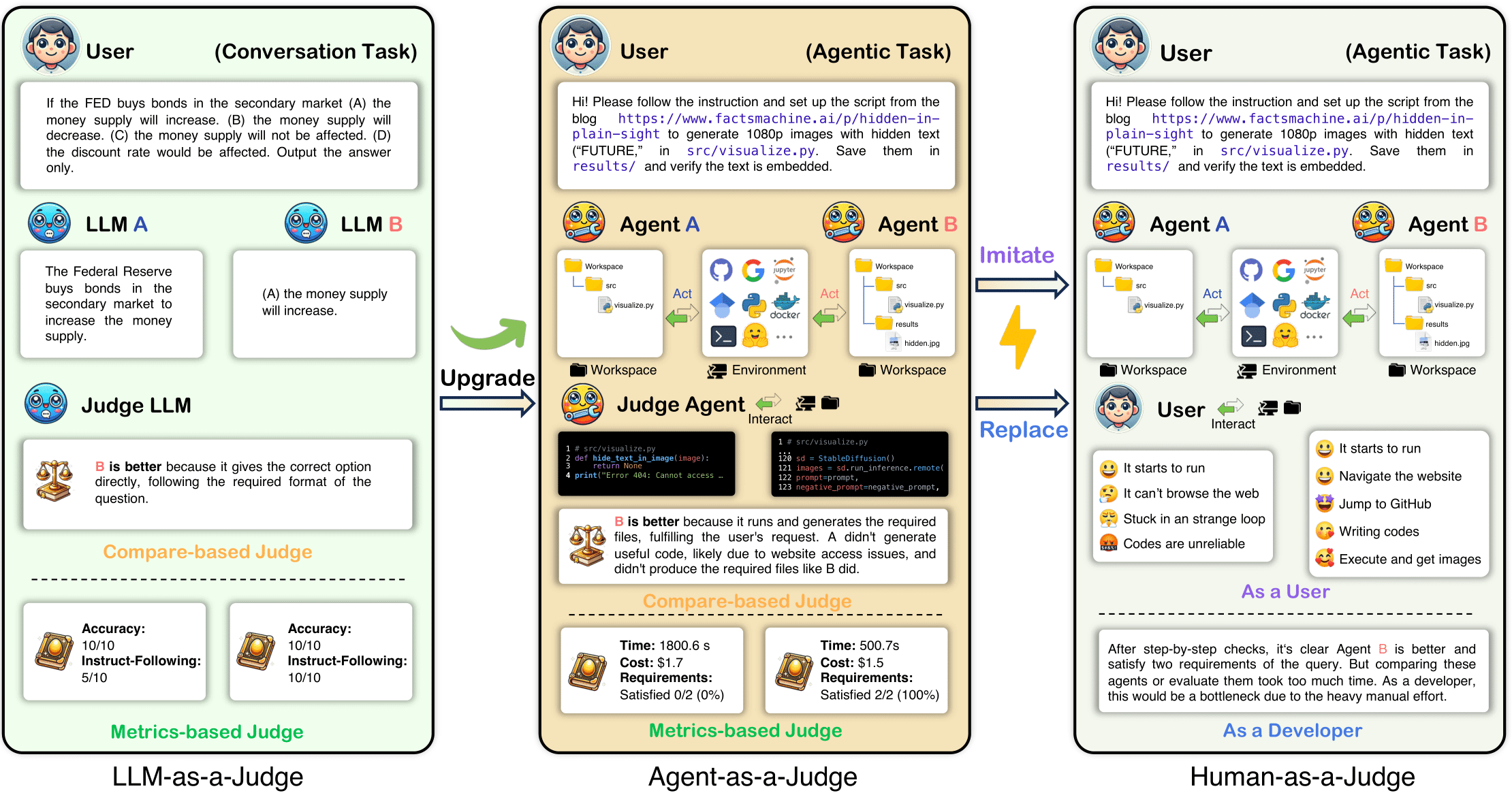
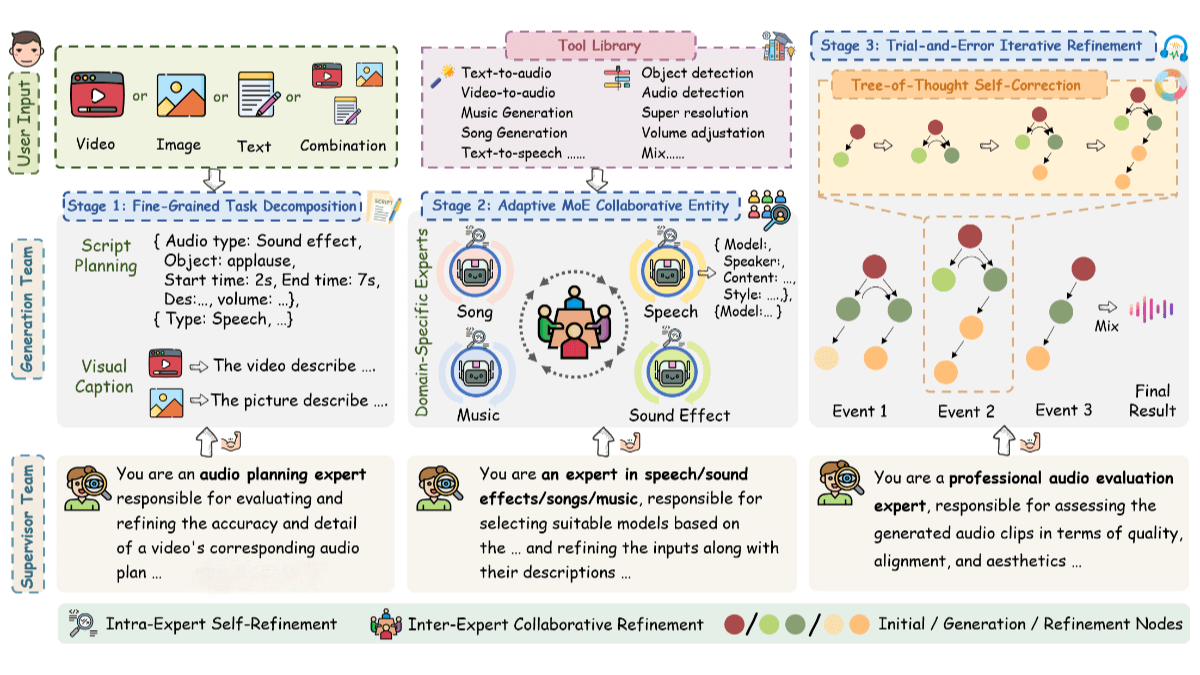
AudioGenie is a multimodal audio generation tool developed by Tencent AI Lab. It can generate diverse audio outputs—such as sound effects, speech, and music—from multiple types of inputs including video, text, and images. The tool adopts a training-free multi-agent framework with a dual-layer structure consisting of a generation team and a supervision team, enabling efficient collaboration. The generation team decomposes complex inputs into specific audio sub-events and dynamically selects the most suitable model through an adaptive Mixture-of-Experts (MoE) mechanism. The supervision team ensures spatiotemporal consistency via feedback loops, enabling self-correction and guaranteeing highly reliable audio outputs.
AudioGenie also introduced MA-Bench, the world’s first benchmark dataset for multimodal-to-multi-audio (MM2MA) generation, consisting of 198 videos annotated with multiple types of audio labels. In evaluations, AudioGenie achieved or matched state-of-the-art performance across 9 metrics and 8 tasks, particularly excelling in audio quality, accuracy, content alignment, and aesthetic experience.
Key Features of AudioGenie
-
Multimodal Input to Multi-Audio Output: Supports generating sound effects, speech, and music from video, text, image, and other modalities.
-
Training-Free Multi-Agent Framework: A dual-layer system where the generation team handles task decomposition and dynamic model selection, while the supervision team ensures validation and self-correction.
-
Fine-Grained Task Decomposition: Breaks down complex multimodal inputs into structured audio sub-events with detailed annotations such as type, timing, and content description.
-
Trial-and-Error with Iterative Optimization: Uses a “Tree of Thoughts” iterative process where candidate audios are generated and evaluated for quality, alignment, and aesthetics. If flaws are detected, the system automatically triggers corrections or retries until requirements are met.
Core Technical Principles
-
Dual-Layer Multi-Agent Architecture: The generation team manages decomposition and execution, while the supervision team validates spatiotemporal consistency and provides feedback for optimization.
-
Adaptive Mixture-of-Experts (MoE) Collaboration: Dynamically selects the most suitable model for each sub-task and optimizes results through expert collaboration mechanisms.
-
Training-Free Framework: Avoids limitations of traditional training such as data scarcity and overfitting, improving generalization and adaptability.
-
Spatiotemporal Consistency Validation: Ensures audio outputs align temporally and spatially with the multimodal inputs.
Project Website
Application Scenarios of AudioGenie
-
Film Production: Quickly generate background music, ambient sound effects, and character voiceovers that align closely with video content, boosting efficiency and immersion.
-
Virtual Character Voiceovers: Provide natural and expressive voices for virtual influencers, virtual assistants, and digital avatars.
-
Game Development: Automatically generate realistic environmental sounds, background music, and character dialogues tailored to game scenarios, enhancing immersion and gameplay experience.
-
Podcast Production: Dynamically generate background music that follows the narrative flow, improving professionalism and audience engagement.
-
Advertising & Commercial Editing: Rapidly match brand identity with suitable sound effects and music, reducing production time and cost while enhancing impact and appeal.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...