
What is Klear-Reasoner?
Klear-Reasoner is a reasoning model released by Kuaishou, built on Qwen3-8B-Base and specialized in enhancing mathematical and coding reasoning. The model is trained through long chain-of-thought supervised fine-tuning (long CoT SFT) and reinforcement learning (RL). Its core innovation is the GPPO algorithm, which preserves clipped gradient information to address the limitations of traditional methods—restricted exploration capability and slow convergence of negative samples. On benchmarks such as AIME and LiveCodeBench, Klear-Reasoner has achieved top-tier performance among 8B-parameter models. Its training details and end-to-end process are fully open, providing valuable references and reproducibility paths for reasoning model development.
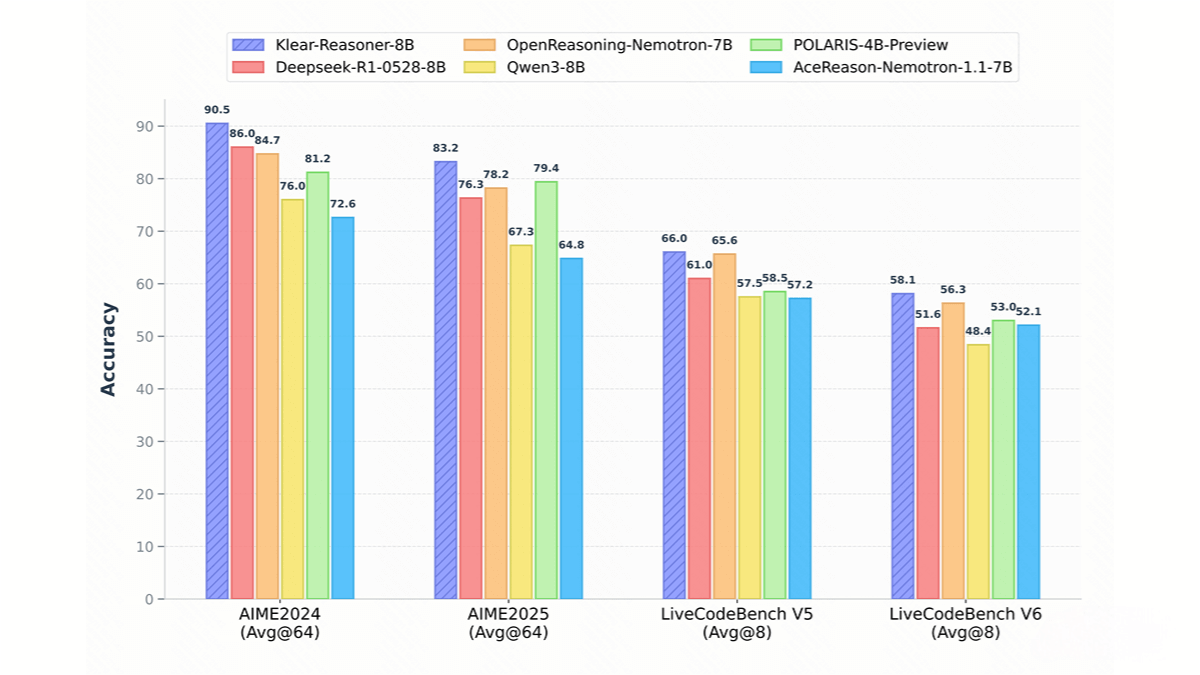
Key Features of Klear-Reasoner
-
Mathematical Reasoning: Excels at solving complex mathematical problems, including challenging competition-level tasks.
-
Code Generation & Reasoning: Generates high-quality code, achieving 66.0% and 58.1% accuracy on LiveCodeBench V5 and V6, respectively.
-
Long Chain-of-Thought Reasoning: Handles multi-step reasoning tasks through long CoT SFT and RL, improving performance in complex reasoning.
-
Data Quality Optimization: Prioritizes high-quality datasets during training to ensure accurate reasoning patterns, while retaining some error samples to enhance exploration capability.
Technical Principles of Klear-Reasoner
-
Long Chain-of-Thought Supervised Fine-Tuning (long CoT SFT): Uses carefully selected high-quality datasets for supervised fine-tuning. Retains some incorrect samples, especially in difficult tasks, to strengthen exploration ability while avoiding noise from low-quality data.
-
Reinforcement Learning (RL): Improves reasoning abilities, especially in math and coding tasks, with a soft reward mechanism that assigns rewards based on test case pass rates, alleviating reward sparsity. Faulty test case data is filtered out to ensure training quality.
-
GPPO (Gradient-Preserving Clipping Policy Optimization) Algorithm: Unlike traditional PPO and GRPO where clipping discards gradients of high-entropy tokens (limiting exploration and slowing convergence on negatives), GPPO decouples clipping from gradient backpropagation using stop-gradient operations. It preserves gradients for all tokens—constraining high-entropy token gradients within a range and speeding up error correction for negative samples.
-
Soft Reward Mechanism: In code-related RL training, soft rewards (partial credit based on test case pass rate) are more effective than hard rewards (all-or-nothing). This reduces reward sparsity, increases training signal density, lowers gradient variance, and results in a more stable and efficient learning process.
Project Links
-
GitHub Repository: https://github.com/suu990901/KlearReasoner/
-
HuggingFace Model Hub: https://huggingface.co/Suu/Klear-Reasoner-8B
-
arXiv Paper: https://arxiv.org/pdf/2508.07629
Application Scenarios of Klear-Reasoner
-
Education: Acts as an intelligent math tutor, providing step-by-step solutions and reasoning processes to help students better understand and master mathematical concepts.
-
Software Development: Automatically generates high-quality code snippets, assists developers in rapidly building functional modules, and offers code review suggestions to improve quality and efficiency.
-
FinTech: Analyzes financial data for risk assessment and prediction, providing logical reasoning support to help institutions make more precise decisions.
-
Scientific Research & Data Analysis: Handles complex analytical and computational tasks, offering logical reasoning and model explanations to boost research productivity.
-
Intelligent Customer Service: Accurately answers complex user queries with clear reasoning, improving user experience and problem-solving efficiency.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts




No comments yet...