
ReasonIR-8B – A model designed by Meta AI specifically for inference-intensive retrieval tasks
What is ReasonIR-8B?
ReasonIR-8B is a retrieval model developed by Meta AI, specifically designed for reasoning-intensive information retrieval tasks. Based on LLaMA3.1-8B, it adopts a dual-encoder architecture that encodes queries and documents separately into embedding vectors and scores them using cosine similarity. The model integrates the innovative data generation tool ReasonIR-SYNTHESIZER to construct synthetic query-document pairs that simulate real-world reasoning challenges, significantly improving its performance in handling long-context and abstract queries.
Key Features of ReasonIR-8B
-
Complex Query Handling:
Utilizing a dual-encoder architecture, ReasonIR-8B independently encodes queries and documents into embeddings and computes their similarity via cosine scoring. It excels at managing lengthy, cross-domain, and complex queries. The training data includes Varied-Length Queries (VL) with up to 2,000 tokens and Hard Queries (HQ) requiring logical reasoning, enabling the model to process long and abstract inputs effectively. -
Improved Reasoning Accuracy:
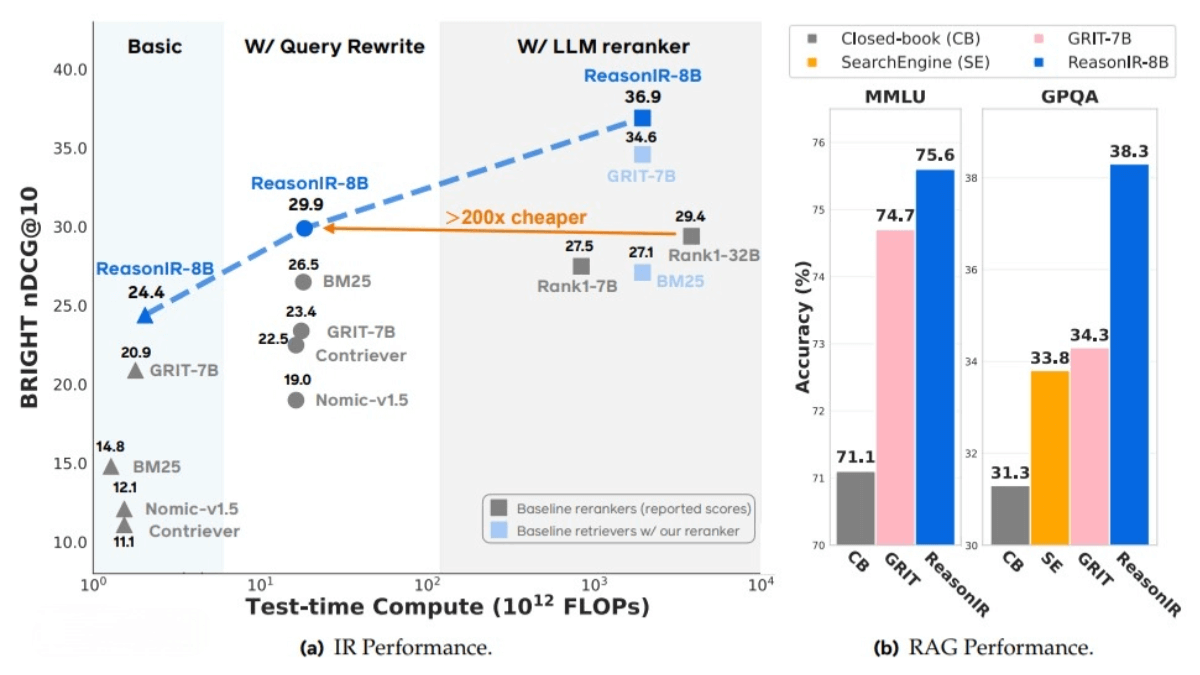
On the BRIGHT benchmark, ReasonIR-8B achieves an original query score of 24.4 nDCG@10, which improves to 36.9 when combined with Qwen2.5 reranking—outperforming much larger models like Rank1-32B at only 1/200th of the computational cost. The model also shows significant improvements in RAG tasks, with 6.4% and 22.6% gains on MMLU and GPQA respectively. -
Synthetic Data Generation:
ReasonIR-8B leverages the ReasonIR-SYNTHESIZER to create synthetic query-document pairs that mimic real-world reasoning scenarios. By using multi-turn prompting, it generates “hard negative” samples, offering more challenging contrastive examples than traditional keyword-matching negatives.
Technical Principles of ReasonIR-8B
-
Dual-Encoder Architecture:
The model encodes queries and documents separately into embeddings and computes similarity using cosine distance. It supports long-form and complex queries, with training data including queries up to 2,000 tokens and reasoning-heavy prompts. -
Varied-Length Data (VL):
Generates synthetic documents for queries of varying lengths, enabling the retriever to handle extended context effectively. -
Hard Query Data (HQ):
Creates reasoning-intensive queries based on high-quality documents and uses multi-turn methods to generate challenging negative samples. -
Public Data:
Combines existing public datasets like MS MARCO and Natural Questions to provide a diverse and balanced training corpus. -
Contrastive Learning:
The model is trained with contrastive learning to bring relevant documents closer to queries in the embedding space while pushing irrelevant ones farther. This training combines synthetic and public data to boost performance on reasoning-heavy tasks. -
Test-Time Optimization:
ReasonIR-8B further improves performance during inference with:-
Query Rewriting: Rewrites original queries into longer, more informative versions using a language model to enhance retrieval quality.
-
LLM Reranking: Reorders retrieved documents using a language model to improve relevance and precision.
-
Project Links for ReasonIR-8B
-
GitHub Repository: https://github.com/facebookresearch/ReasonIR
-
HuggingFace Model Hub: https://huggingface.co/reasonir/ReasonIR-8B
-
arXiv Paper: https://arxiv.org/pdf/2504.20595
Application Scenarios of ReasonIR-8B
-
Complex Question Answering Systems:
Useful in domains like legal advice, medical research, and academic QA, where in-depth reasoning is needed to retrieve relevant documents. -
Education and Learning Tools:
Helps students and educators find background knowledge and reasoning patterns related to complex queries, supporting teaching and self-directed learning. -
Enterprise Knowledge Management:
Enhances internal document retrieval by helping employees find solutions and context for complex issues within corporate knowledge bases. -
Research and Development:
Assists researchers in quickly locating relevant literature, experimental results, and methodologies, accelerating the pace of scientific inquiry.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...