Absolute Zero – Tsinghua-Led Language Model Reasoning & Training Method
What is Absolute Zero
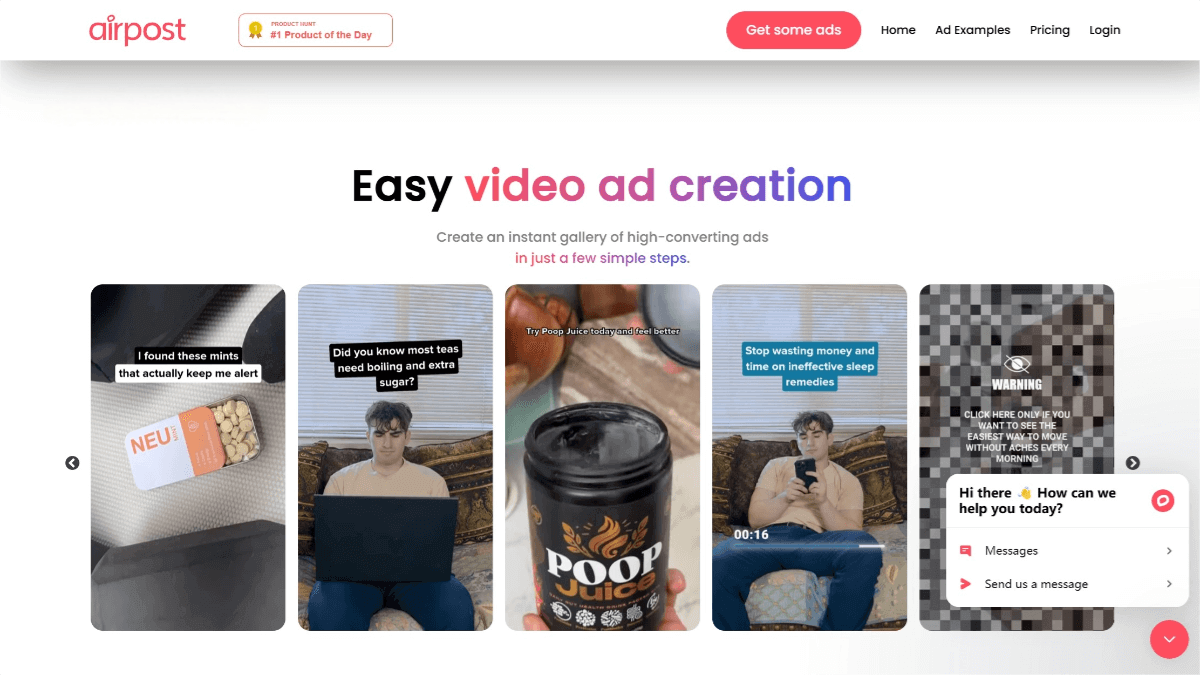
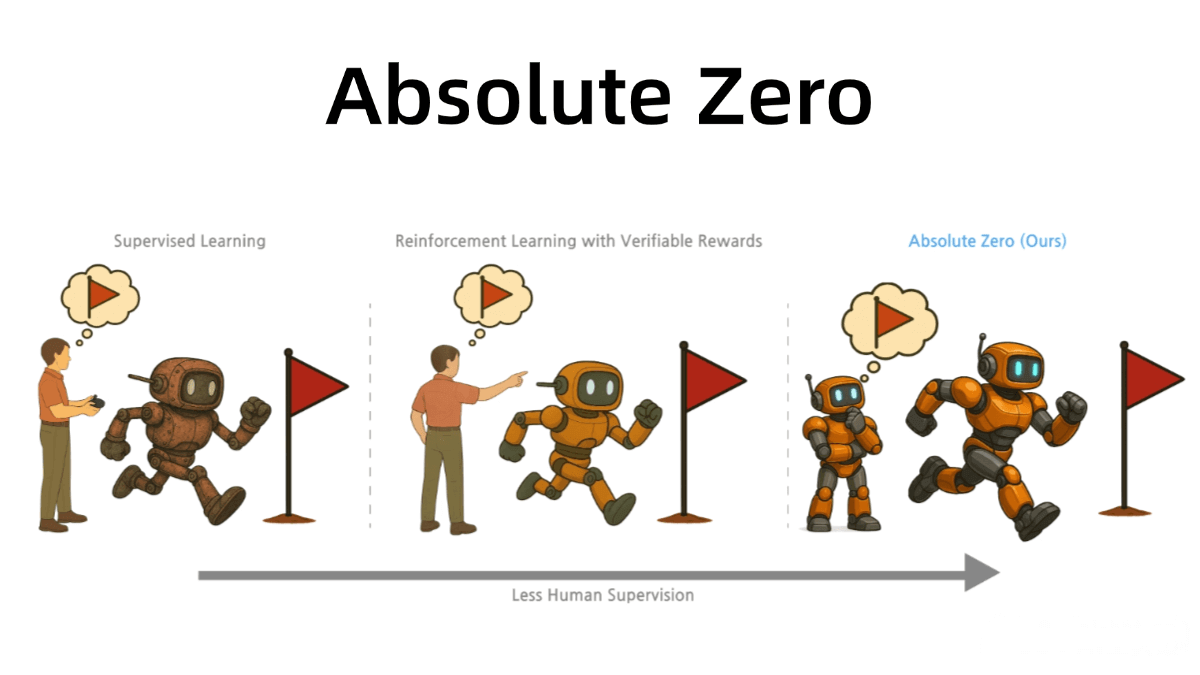
Absolute Zero is a novel language model reasoning and training framework developed by the LeapLab team at Tsinghua University, in collaboration with the NLCo Lab at the Beijing Institute for General Artificial Intelligence and Pennsylvania State University. Absolute Zero enables models to autonomously generate and solve tasks through self-evolutionary learning—without relying on human-labeled data or predefined tasks. The model receives a learnability reward when generating tasks and an answer reward when solving them, continuously enhancing its reasoning capabilities through interaction with its environment. At its core, Absolute Zero shifts reasoning models from human-supervised learning to environment-supervised learning, using real-world feedback to generate verifiable tasks and improve performance.
Key Features of Absolute Zero
-
Autonomous Task Generation: The model independently proposes tasks that are neither too simple nor too complex, offering effective learning signals.
-
Autonomous Task Solving: Acting as a solver, the model attempts to solve its self-generated tasks, using environmental feedback to verify correctness.
-
Enhanced Reasoning Ability: By continuously generating and solving tasks, the model strengthens its reasoning skills, including induction, deduction, and abduction.
-
Cross-Domain Generalization: The reasoning skills acquired through self-learning can be transferred to new tasks and domains.
-
Zero Data Training: Learning occurs entirely through interaction and feedback from the environment, without any reliance on human-labeled data or manually designed tasks.
Technical Principles Behind Absolute Zero
-
Dual-Role Architecture: The model simultaneously acts as a Task Proposer and a Task Solver. The proposer generates tasks, while the solver attempts to solve them. Both roles share model parameters and are jointly optimized.
-
Environmental Feedback Mechanism: The model interacts with the environment (e.g., a code executor) to validate task solvability. Task generation is rewarded based on learnability (task difficulty and solver success rate), and solving is rewarded based on solution correctness.
-
Reinforcement Learning Optimization: The model is optimized using reinforcement learning algorithms such as TRR++ that combine learnability and solution rewards, enabling self-evolution across diverse tasks.
-
Support for Reasoning Paradigms: Absolute Zero supports three core reasoning types—Deduction, Abduction, and Induction. Each corresponds to specific task formats, allowing the model to target and enhance distinct reasoning skills.
-
Self-Play Learning Loop: The model continuously proposes new tasks, solves them, and updates its strategy based on feedback, forming a closed-loop self-play process. This loop ensures the model improves autonomously without external data.
Project Resources for Absolute Zero
-
Official Website: https://andrewzh112.github.io/absolute-zero-reasoner
-
GitHub Repository: https://github.com/LeapLabTHU/Absolute-Zero-Reasoner
-
Hugging Face Models: https://huggingface.co/collections/andrewzh/absolute-zero-reasoner
-
arXiv Paper: https://www.arxiv.org/pdf/2505.03335
Application Scenarios for Absolute Zero
-
Artificial General Intelligence (AGI): Promotes autonomous learning and self-improvement, advancing toward human-level intelligence.
-
Code Generation: Automatically generates efficient code, solving complex programming tasks and improving development productivity.
-
Mathematical Reasoning: Enhances generalization in solving mathematical problems, aiding math education and research.
-
Natural Language Processing (NLP): Improves language understanding and generation through self-learning, optimizing text generation and QA systems.
-
AI Safety & Ethics: Investigates behavioral patterns in self-evolving AI systems to ensure safety and ethical alignment.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...