What is DragonV2.1?
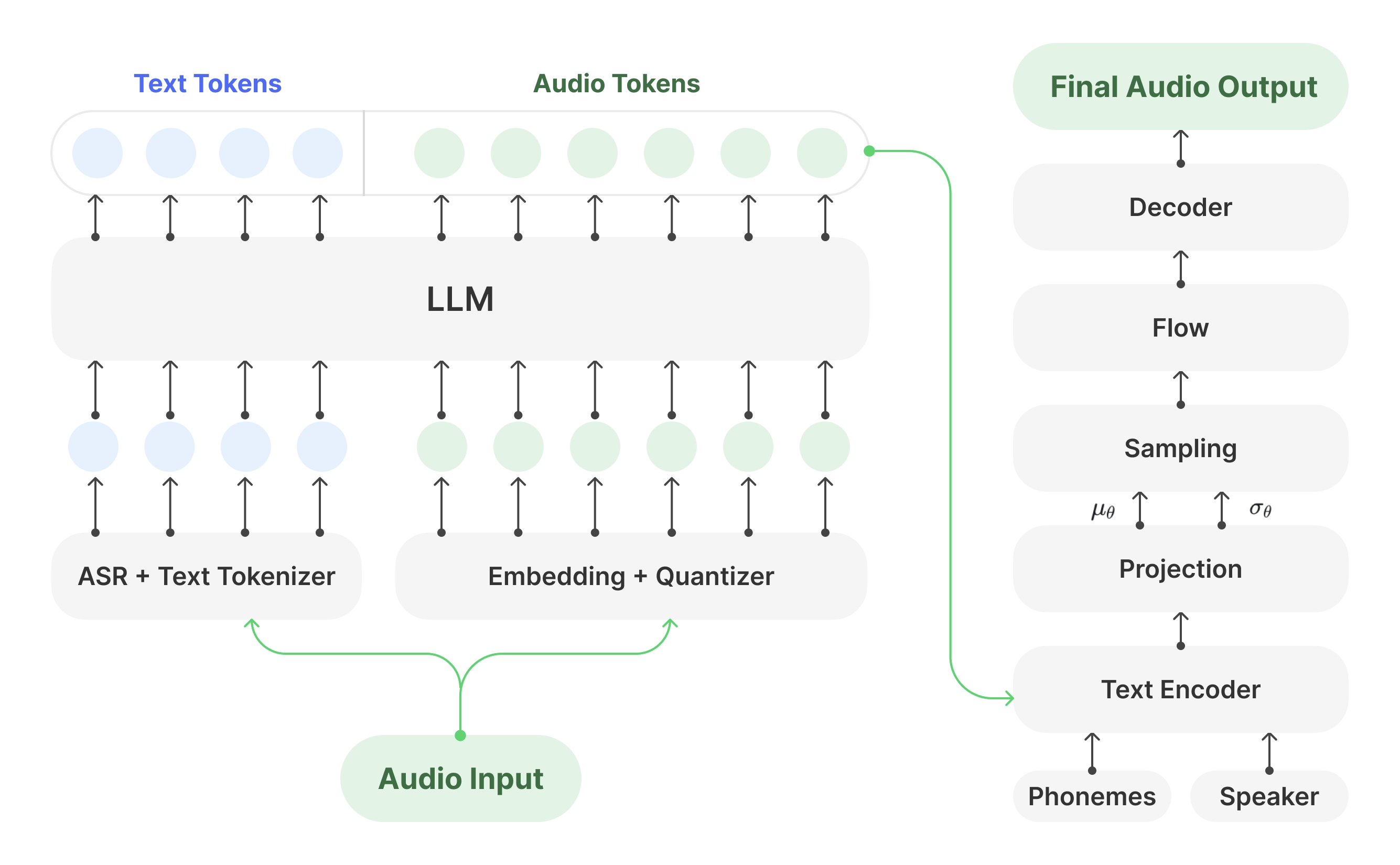
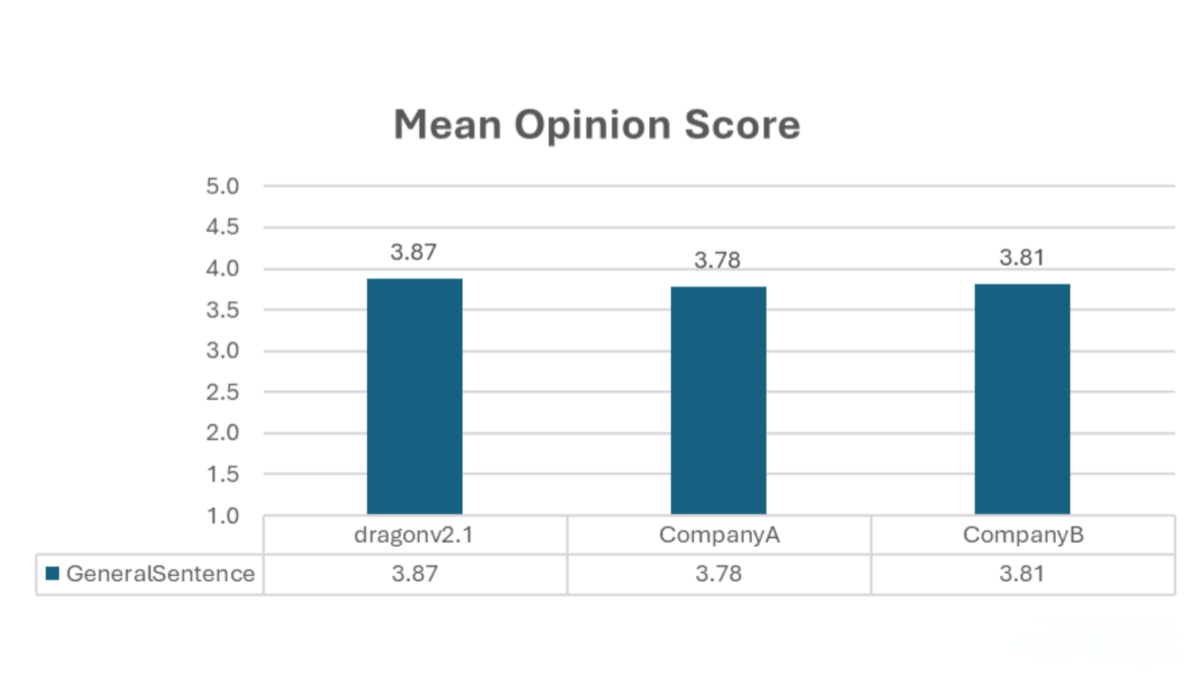
DragonV2.1 (also known as DragonV2.1Neural) is Microsoft’s latest zero-shot text-to-speech (TTS) model. Built on a Transformer architecture, it supports multilingual synthesis and zero-shot voice cloning. With just 5 to 90 seconds of voice prompts, the model can generate natural and expressive speech. DragonV2.1 brings significant improvements in pronunciation accuracy, naturalness, and controllability. Compared to DragonV1, it reduces word error rate (WER) by an average of 12.8%. It supports SSML phoneme tags and custom dictionaries, enabling precise control over pronunciation and accents. The model also integrates watermarking technology to ensure compliance and security in speech synthesis.
Key Features of DragonV2.1
-
Multilingual Support: Compatible with over 100 Azure TTS locales, enabling speech synthesis in a wide range of languages to meet diverse user needs.
-
Emotion and Accent Adaptation: Adjusts speech emotion and accent dynamically based on context, making the output more expressive and personalized.
-
Zero-Shot Voice Cloning: Requires only 5 to 90 seconds of audio to create a custom AI voice clone, significantly lowering the barrier for personalized voice synthesis.
-
Fast Generation: Capable of producing high-quality synthesized speech with a latency of less than 300ms and a real-time factor (RTF) below 0.05—ideal for real-time applications.
-
Pronunciation Control: Supports phoneme tags in SSML (Speech Synthesis Markup Language), allowing users to control pronunciation precisely using IPA tags and custom dictionaries.
-
Custom Dictionaries: Enables users to define specific pronunciations for custom vocabulary, ensuring speech accuracy.
-
Language and Accent Control: Allows generation of speech in specific languages and accents, such as British English (en-GB) and American English (en-US).
-
Watermarking Technology: Automatically embeds watermarks in the synthesized audio to prevent misuse and ensure traceability.
Technical Foundation of DragonV2.1
-
Transformer Architecture: DragonV2.1 is based on the Transformer architecture, a deep learning framework widely used in NLP and TTS. It employs self-attention mechanisms to handle input sequences, capturing long-range dependencies and producing fluent, coherent speech.
-
Multi-Head Attention: This mechanism allows the model to attend to different parts of the input from multiple perspectives, enhancing its ability to capture detailed speech features.
-
SSML Support: SSML is a markup language used to control various aspects of speech synthesis. DragonV2.1 supports SSML phoneme tags and custom lexicons, giving users fine-grained control over pronunciation, intonation, rhythm, and more.
Project Page for DragonV2.1
Application Scenarios of DragonV2.1
-
Video Content Creation: Generate multilingual dubbing and real-time subtitles while preserving the original speaker’s style, enhancing global viewer experience.
-
Intelligent Customer Service and Chatbots: Produce natural and expressive voice responses in multiple languages to improve customer experience and reduce service costs.
-
Education and Training: Generate speech in various languages to assist with pronunciation and listening practice, improving engagement in online courses.
-
Smart Assistants: Provide natural, multilingual voice interactions for smart home devices and in-vehicle systems, enhancing usability.
-
Enterprise and Branding: Create branded voices for advertising and marketing campaigns, supporting multilingual delivery to boost brand recognition and global reach.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...