
StepAudio R1 – the open-source native audio reasoning model developed by StarEvo (Jieyue Xingchen)
What is StepAudio R1?
StepAudio R1 is the world’s first open-source native audio reasoning model released by the StepFun (Jieyue Xingchen) team. With its innovative Modality-Grounded Reasoning Distillation (MGRD) framework, the model overcomes the common degradation in reasoning performance found in traditional audio models when facing complex tasks. It enables true reasoning grounded in acoustic features rather than text.In multiple benchmarks, StepAudio R1 surpasses Gemini 2.5 Pro and performs on par with Gemini 3. It delivers extremely strong real-time reasoning, achieving a 96% score and only 0.92 seconds first-token latency. The model opens a new path for multimodal reasoning in the audio domain and is widely used in music analysis, film/TV dialogue interpretation, interview analysis, and more—bringing a breakthrough to intelligent audio understanding.
Main Features of StepAudio R1
1. Complex Audio Reasoning
StepAudio R1 can handle sophisticated reasoning tasks based on audio, such as understanding implicit meanings in conversations, analyzing emotions, and inferring character traits.
2. Real-Time Audio Reasoning
The model supports powerful real-time reasoning with extremely low latency (e.g., 0.92 s first-token latency), making it ideal for real-time dialogue and interactive scenarios.
3. Multimodal Reasoning Ability
While natively focused on audio, the model also integrates text-based reasoning, enabling it to serve as a universal solution for multimodal reasoning tasks.
4. Emotional & Social Intelligence Reasoning
It can analyze emotions, personality traits, social relationships, etc. For example, it can infer a speaker’s psychological state, personality, or social identity from conversations.
Technical Principles of StepAudio R1
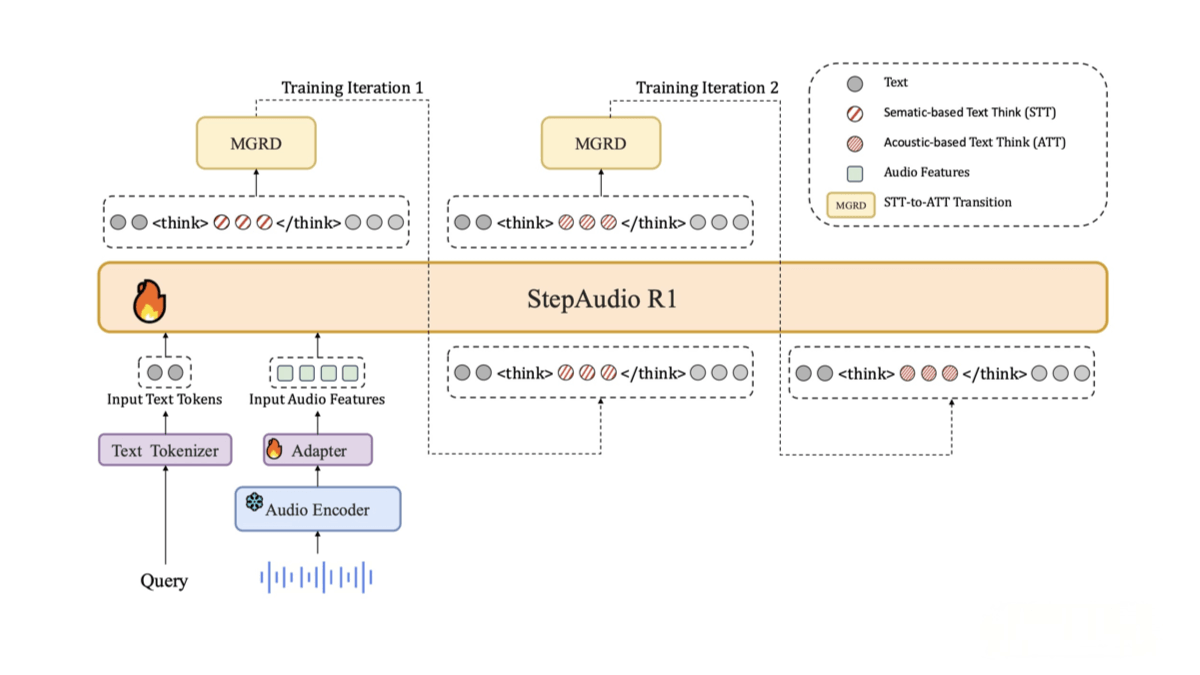
1. Modality-Grounded Reasoning Distillation (MGRD)
The core technology of StepAudio R1 is MGRD, which iteratively distills reasoning ability from textual abstraction into acoustic attributes.
This solves the misalignment between reasoning chains and the audio modality seen in traditional models, enabling the model to generate reasoning that truly stems from audio signals.
2. Audio Feature Extraction & Alignment
The model first extracts key audio features—such as intonation, rhythm, and emotional cues—and aligns them with reasoning tasks through the MGRD framework.
This ensures its reasoning is grounded in audio characteristics rather than relying on transcription or other modalities.
3. Multimodal Fusion
StepAudio R1 retains strong text reasoning capabilities, making it powerful in multimodal scenarios such as joint audio-text emotion analysis and content understanding.
Project Resources
-
Official Website: https://stepaudiollm.github.io/step-audio-r1/
-
GitHub Repository: https://github.com/stepfun-ai/Step-Audio-R1
-
HuggingFace Model Page: https://huggingface.co/stepfun-ai/Step-Audio-R1
-
arXiv Paper: https://arxiv.org/pdf/2511.15848
Application Scenarios of StepAudio R1
1. Music Appreciation
Analyzing melody, lyrical emotion, and stylistic features to help users better understand musical works.
2. Film & TV Dialogue Analysis
Interpreting dialogue, inferring characters’ emotions, personalities, and relationships to deepen story understanding.
3. Interview Analysis
Identifying key information, emotional tendencies, and logical structure from interview recordings.
4. Academic Presentation Analysis
Helping researchers examine the logic and key ideas in academic talks, improving communication and analysis skills.
5. Emotion Analysis
Detecting emotional states (e.g., happiness, sadness, anger) through intonation, rhythm, and word usage in audio.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts




No comments yet...