
Qwen3-30B-A3B-Instruct-2507 – a non-thinking mode model open-sourced by Alibaba Tongyi
What is Qwen3-30B-A3B-Instruct-2507
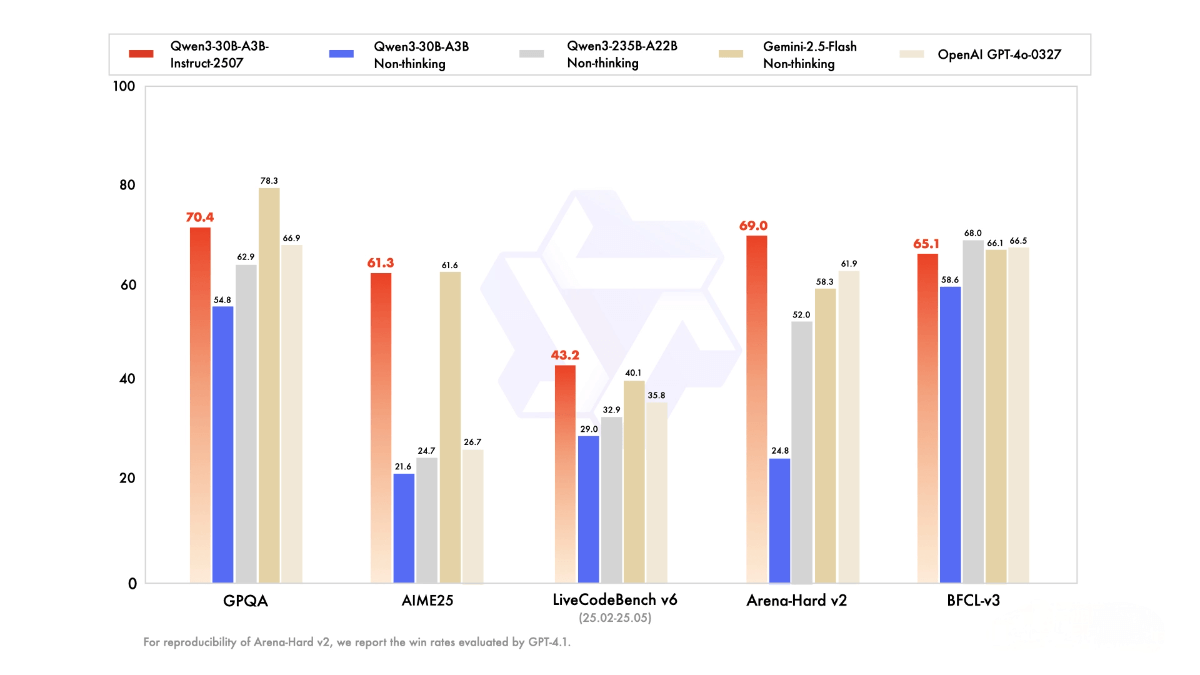
Qwen3-30B-A3B-Instruct-2507 is an open-source non-thinking mode language model by Alibaba Tongyi, with a total of 30.5 billion parameters and 3.3 billion active parameters. It has 48 layers and supports a context length of 262,144 tokens. The model excels in instruction following, logical reasoning, and multilingual knowledge coverage, making it especially suitable for local deployment with relatively low hardware requirements. It can be efficiently deployed using sglang or vllm and is a powerful tool for developers and researchers. It is currently accessible through Qwen Chat.
Key Features of Qwen3-30B-A3B-Instruct-2507
-
Instruction Following
Accurately understands and executes user instructions to generate compliant text outputs. -
Logical Reasoning
Strong capability in logical reasoning, handling complex logic problems and inference tasks. -
Text Understanding and Generation
Understands and produces high-quality text suitable for various NLP tasks such as writing, translation, and Q&A. -
Mathematical and Scientific Problem Solving
Excels in solving complex math and science problems with advanced calculation and reasoning. -
Coding Ability
Supports code generation and programming-related tasks, helping developers quickly fulfill coding needs. -
Multilingual Support
Covers multiple languages with strong cross-lingual understanding and generation capabilities. -
Long-Text Processing
Supports a context window of up to 262,144 tokens, suitable for long input and generation tasks. -
Tool Invocation
Based on Qwen-Agent, supports calling external tools to enhance practical usability.
Technical Principles of Qwen3-30B-A3B-Instruct-2507
-
Mixture of Experts (MoE)
With 30.5 billion total parameters and 3.3 billion active parameters, the model uses a sparse activation mechanism. It contains 128 experts, activating 8 experts per input dynamically, which improves efficiency and flexibility while maintaining performance. -
Causal Language Model
Built on a Transformer architecture with 48 layers, each with 32 query heads and 4 key-value heads. It handles long sequences effectively with support for a 262,144-token context length, suited for scenarios requiring long-context understanding. -
Pretraining
Trained on large-scale text data to learn general language features and patterns. -
Fine-tuning
Further fine-tuned on task-specific datasets to boost performance on specialized tasks.
Project Resources
-
HuggingFace Model Hub: https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507
Application Scenarios of Qwen3-30B-A3B-Instruct-2507
-
Writing Assistance
Helps writers and content creators rapidly generate high-quality text, improving writing efficiency. -
Intelligent Customer Service
Builds smart customer support systems to automatically answer queries, enhancing satisfaction and response speed. -
Programming Assistance
Generates code snippets, optimization suggestions, and API documentation for developers to improve productivity and code quality. -
Educational Tutoring
Provides answers to academic questions and learning support for students, assisting teachers in generating teaching materials and exercises. -
Multilingual Translation
Supports translation across multiple languages, facilitating cross-language communication and international content generation.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...